Houston Community College Planning
I worked with a small team to determine the best location to place a community college in Houston by analyzing data from Houston census tracts.
Main Python Skills Used
-
Creating/manipulating Pandas dataframes
-
Selecting/organizing statistics
Background
The purpose of this project was to identify the best neighborhood to place a community college in Houston with the goal of maximizing equity. My team did this by analyzing variables relating to race, income, education levels, and age in different neighborhoods.
Process
-
Organized 3 given CSV files with information data including Houston census tracts into a Pandas dataframe
-
Created a smaller dataframe isolating 6 possible locations and 6 variables/columns of interest that we wanted to evaluate
-
Coded a ranking system that would rank the neighborhoods based on each variable (ex: more points for a higher population, more (negative) points for higher income)
-
Scaled each variable's points by importance (ex: "not high school grad rank" was scaled by 3x because it was more important compared to other variables)
-
Output the final scores (adding up the neighborhood’s 6 rankings), determining which neighborhood had the highest score and in turn would benefit the most from the addition of a community college
Outputs + Conclusions
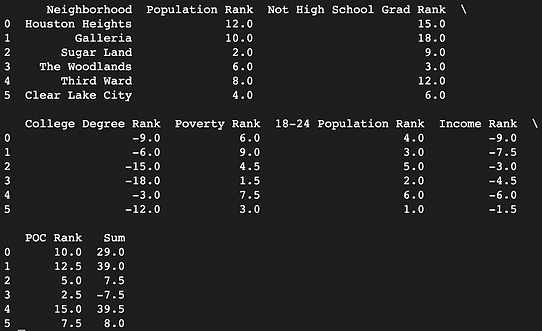
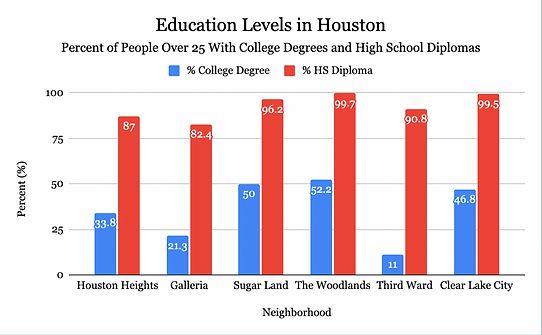
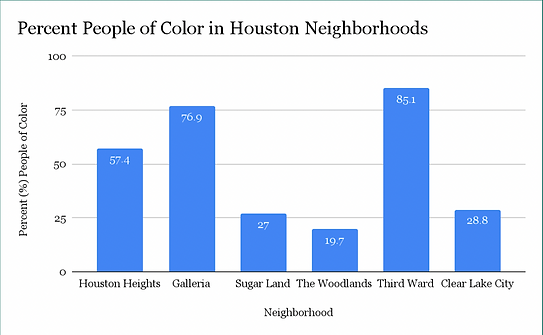
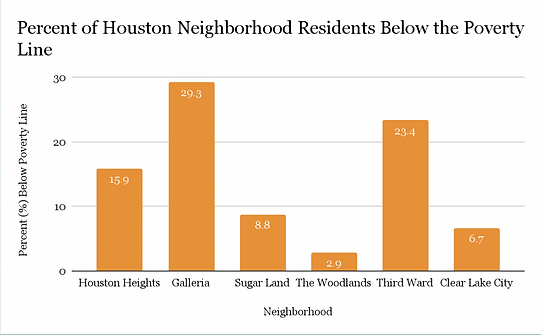
Based on the sum of the rankings of each neighborhood, we concluded that Third Ward would be the best place to put the community college because it had the highest sum of points.